Blog
Faster KEYS and SCAN: Optimized glob-style patterns in Redis 8
For years, the standard guidance around Redis search on Strings has been simple: use KEYS with extreme care - or avoid - in production (reference here), and treat SCAN carefully as iterative scanning can take a long time to complete even if it does not block the server. That guidance was correct for standalone and pre‑Redis 8 cluster deployments where these commands had to walk entire keyspaces or full shards.
With Redis 8 and the glob-style pattern optimization for clustered deployments, that story changes for a specific - but very powerful - class of patterns. Under the right conditions, commands like KEYS and SCAN can become fast, narrowly scoped lookups that are realistic for online search and indexing workloads.
In this post we’ll cover:
- How the glob-style pattern optimization works
- A generic per-user activity example showing how to design keys for it
- High-level benchmark results
- Practical guidelines for safely using KEYS and SCAN in this new world
Before diving in: When (and for whom) this optimization actually matters
Before we get into hash slots and glob rules, it’s worth grounding when this optimization actually matters, who it helps, and what difference it can make. This isn’t about making arbitrary KEYS calls “a bit faster.” It’s about a specific, common class of workloads that already lean on well-structured String keys and need predictable, low-latency lookups over a small subset of those keys.
When does it matter?
- You are running Redis in cluster mode and care about tail latency and blast radius.
- You have high-cardinality entities (users, tenants, accounts, sessions, devices, etc.) with a set of keys per entity.
- You already store data as plain Strings for footprint or simplicity, and a separate indexing structure (Sets, Sorted Sets, a search index, or another store) feels like unnecessary overhead for this one access pattern.
Your access pattern is mostly: “fetch all keys for one logical entity”, not “search the entire keyspace with wildcards”.
Who does it matter for?
- Teams building personalization, activity, or per-entity views: user activity streams, account timelines, event logs, per-tenant configuration, per-session traces, and similar.
- Teams that already use Redis as a primary online store and want to avoid adding another index or service just to support a simple “grouped keys by ID” lookup.
Teams that need to keep operational complexity low (fewer moving parts, fewer background jobs, less reindexing) while still hitting strict latency SLOs.
What difference can it make?
- Turns KEYS / SCAN from “global walkers” into targeted lookups by constraining work to a single hash slot when patterns are designed correctly.
- Avoids building and maintaining extra indexing structures just to answer “get all keys for this user/tenant/account”, reducing memory, ops, and failure modes.
- Unlocks online use of KEYS/SCAN for specific patterns where they were previously off the table in production, because latency and impact become bounded by the small number of keys in one slot rather than the size of the whole cluster.
- In practice, this can be the difference between a design being “probably a no-go” (because it implies expensive cluster-wide scans or new infrastructure) and being a viable, simple solution built directly on top of your existing String key layout.
Background: Hash slots, hash tags, and glob-style optimization
Redis Cluster splits the keyspace into 16,384 hash slots, each served by a single primary node in a stable configuration. The slot for a key is:
To support co-location of related keys (for multi-key operations and data locality), Redis Cluster introduces hash tags: if a key contains {...}, only the substring inside the first well‑formed {} pair is hashed.
Examples:
- {user1000}:following and {user1000}:followers always land in the same hash slot (hash tag: user1000).
- foo{}{bar} hashes the full key (empty tag is ignored).
- foo{{bar}}zap hashes {bar.
- foo{bar}{zap} hashes bar.
Redis 8: pattern-slot optimization for KEYS / SCAN / SORT
Starting in Redis 8, commands that accept a glob-style pattern – including KEYS, SCAN and SORT – can detect when a pattern must map to a single hash slot and then restrict the search to only that slot, instead of scanning the entire database or all slots in a shard.
The optimization is applied when all of the following are true:
- The pattern contains a hash tag.
- There are no wildcards or escape characters before the hash tag.
- The substring inside { ... } (the tag itself) contains no wildcards or escapes.
Examples:
- Optimized: SCAN 0 MATCH {abc}* → scans only the slot for abc
- Not optimized: *{abc}, {a*c}, {a\*bc} → may match keys in many slots, so all slots must be scanned
This pattern-slot optimization is what turns KEYS and SCAN from “global keyspace walkers” into “single-slot index lookups” – if you design your keys and patterns for it.
A generic example: Per-user activity streams
To make this concrete, consider a generic user activity workload:
- You store recent activity events in Redis as Strings to minimize memory footprint.
- You need to fetch all events for a given user – e.g., to build an activity feed, compute aggregates, or debug sessions.
- You’d prefer not to build and maintain separate secondary structures (Sets / Sorted Sets / Hashes / Search indexes) if you can avoid the memory and operational overhead.
A simple key/value design might be:
To make this work well with the glob optimization, we embed the user ID as a hash tag:
For a given user, we can search with:
This pattern:
- Contains a valid hash tag {user_123}.
- Has no wildcard before the tag.
- Has no wildcard inside the tag.
Any key that matches this pattern must live in exactly one hash slot, so Redis 8 can restrict SCAN/KEYS/SORT to that slot only.
You can substitute userId with any other grouping dimension: customerId, tenantId, accountId, sessionId, etc.
Test setup (high level)
To understand how much this optimization changes behavior, we ran a series of internal benchmarks using the following setup:
| Databases | Redis OSS 7.2 (pre-optimisation) Redis OSS 8.4 (post-optimisation) |
| Dataset | 5,000,000 keys |
| Key Pattern | app:eu:{user_id}:event_id |
| Cluster | 3 nodes |
| Benchmark Runs | 10 iterations per test |
| Search Pattern | app:eu:{user_12345}:* |
Benchmarks
7.2 Cluster
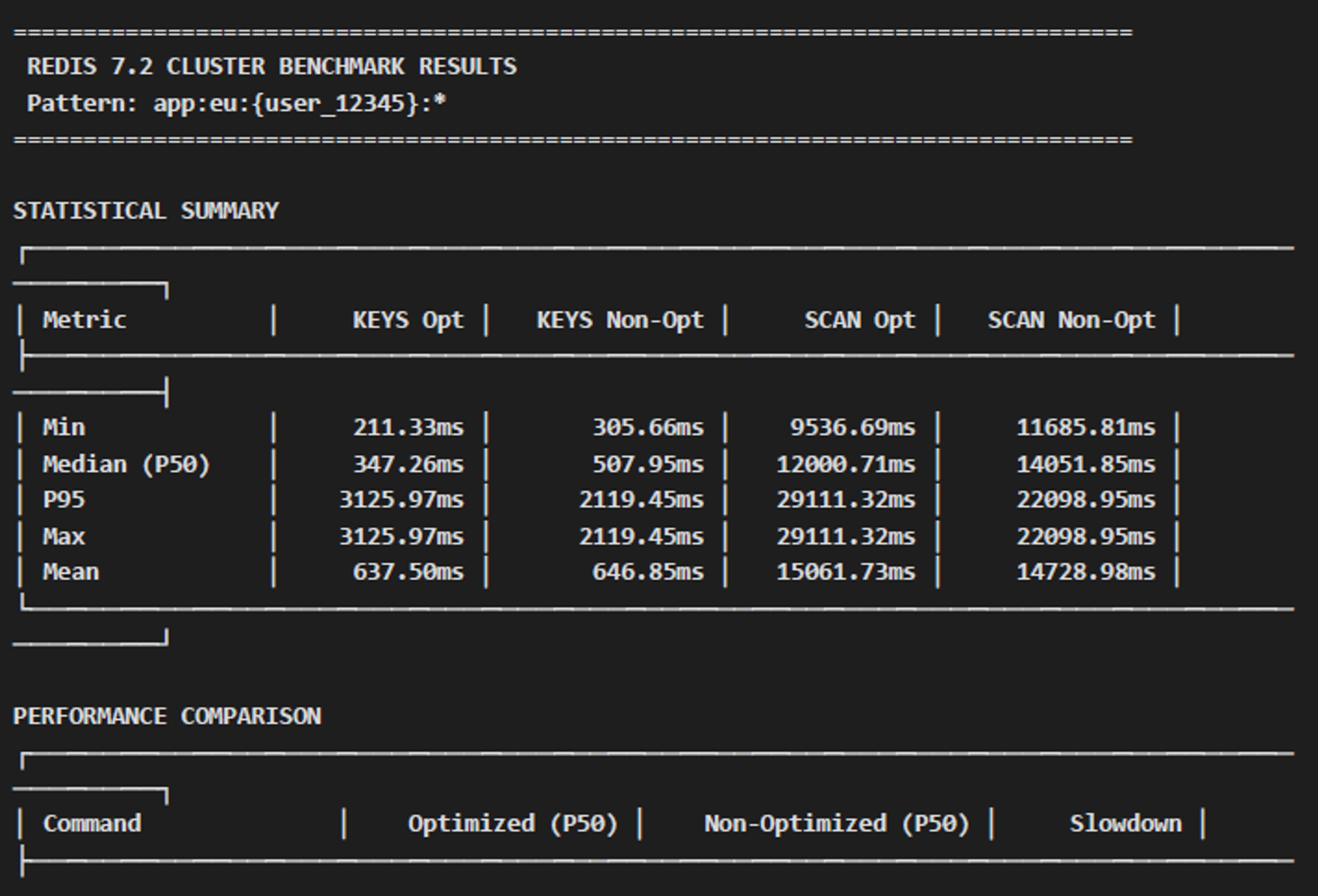
In Redis 7.2, the performance of both patterns is comparable, as the optimization was not yet implemented. Both methods necessitate scanning all cluster nodes, which accounts for the slow performance, with SCAN operations requiring between 12 and 14 seconds.
8.4 Cluster
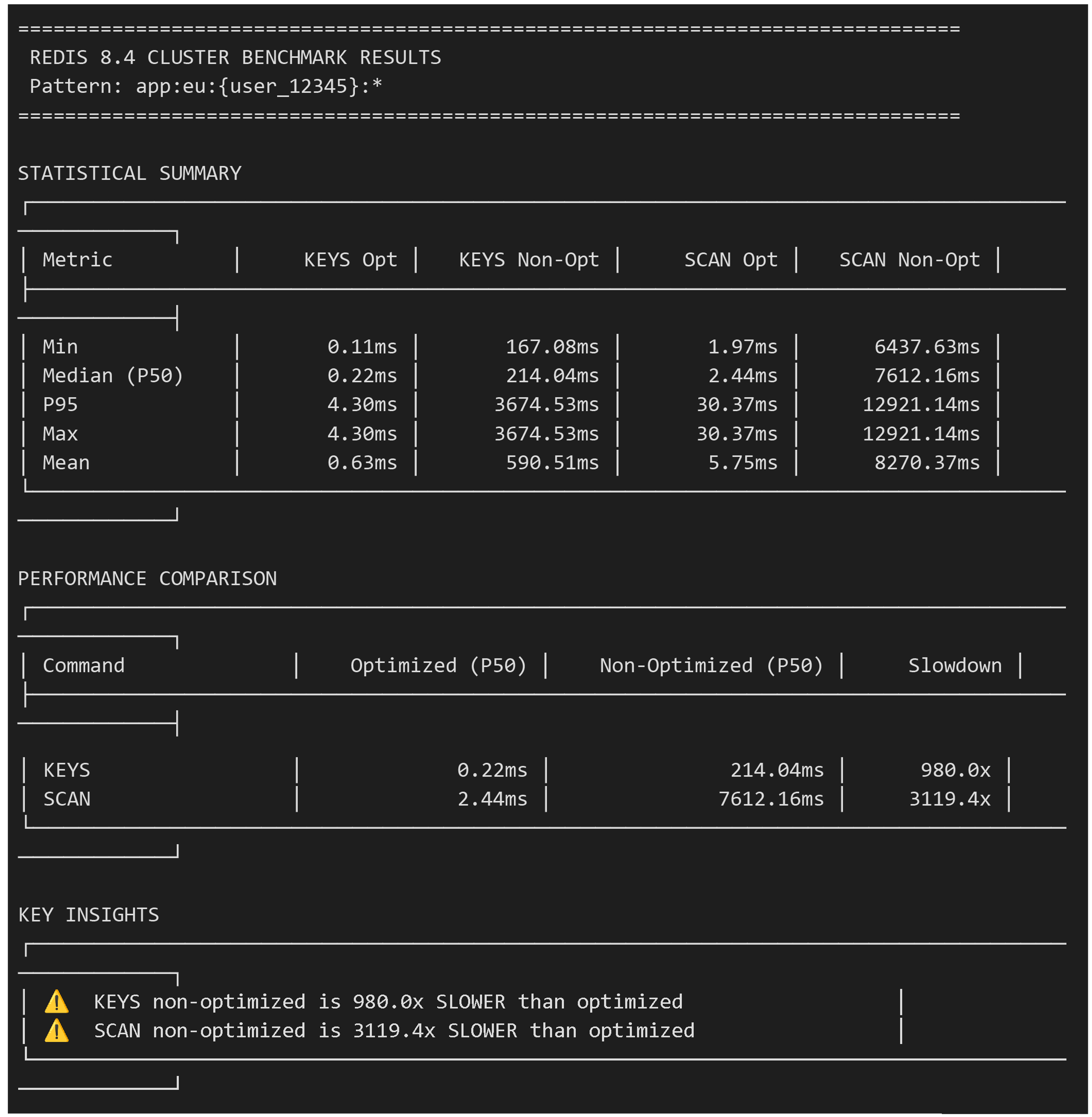
Redis 8.4 demonstrates the profound effect of the optimization:
- Optimized SCAN: Achieves a median time of 2.44ms by targeting a single hashslot and a 3119.4x improvement over Non-optimized SCAN.
Optimized KEYS: Achieves a median time of 0.22ms by targeting a single hashslot and a 980x improvement over Non-optimized KEYS.
So… is KEYS “safe” now?
The short version: KEYS can be viable in production – if you design for the optimization and respect its constraints. It is not a blanket recommendation.
When KEYS (and SCAN) become realistic options
KEYS and SCAN are reasonable for online queries when all of the following are true:
- Pattern implies exactly one hash slotYour key design and glob pattern satisfy the glob-style optimization rules:
- A non-wildcard hash tag inside {}.
- No wildcards or escape characters before the tag.
- No wildcards or escapes inside the tag.
- Database is running in cluster mode with the optimization enabledIn Redis Cloud / Redis Software, this usually means cluster mode + Flexible Sharding so the pattern-slot optimization is active for those commands.
- Per-slot cardinality is small and boundedEach hash slot you query via KEYS/SCAN should contain a small, predictable number of keys for that pattern (e.g., a handful of events per user). This keeps blocking windows and response sizes under tight control.
- You validate under realistic loadYou should run load tests and watch:
- Server-side latency histograms
- p50 / p99 / p99.9 latency for your commands
- Per-shard CPU and command mix
When you should still avoid KEYS
You should still be very cautious with KEYS (and treat SCAN carefully) when:
- Your patterns don’t map to a single hash slot (e.g., app:*, *{user_*}, or tags with wildcards).
- The per-slot cardinality is large – tens or hundreds of thousands of keys per tag will still need testing to validate whether the solution is viable.
- You’re on non-clustered deployments or cluster configs where the optimization is not available.
- The operation sits in a hard real-time path with strict p99 budgets and no tolerance for occasional outliers.
In those scenarios, a dedicated index – e.g., Sorted Sets, Hash-based secondary keys, or Redis Query Engine / Search over Hash/JSON – remains the safer and more flexible approach.
Practical guidelines for using optimized glob-style search
If you want to exploit this optimization in your own workloads, here’s a concrete checklist:
- Pick your grouping dimension
Common choices:
- userId
- customerId
- tenantId
- accountId
- sessionId
This is the dimension along which you’ll query “all keys for X.”
2. Embed it as a hash tag in your keyspace
Examples:
- orders:eu:{customer_123}:2025-01-10:<orderId>
- log:us:{user_42}:<eventId>
- cfg:{tenant_7}:feature_flag:<flagName>
3. Ensure your glob patterns respect the optimization rules
- Good (single-slot):log:us:{user_42}:*{account_123}:*
- Not optimized (multi-slot):*:{user_42}:*{user_*}:*{user_42?}:*
4. Decide on your access pattern
- KEYS + MGET for one-shot retrieval of a small group of keys.
- SCAN + MGET for cursor-based paging when a group may grow.
- Lua wrapper around SCAN or KEYS + MGET to:
- Minimize round-trips.
- Keep the logic close to the data.
- Constrain work to a single, small hash slot.
5. Plan an escape hatch
If growth eventually breaks your assumptions (e.g., certain groups accumulate too many keys), be ready to:
- Move that hot path to a secondary index (e.g., Sorted Sets keyed by {groupId}).
- Or adopt Redis Query Engine over Hash/JSON for richer querying, leaving the glob-optimized patterns for narrower, predictable cases.
Conclusions and next steps
The glob-style pattern optimization in Redis 8 opens up a useful new design space:
- For patterns that map cleanly to a single hash slot, SCAN and even KEYS can behave like targeted index lookups, rather than full keyspace scans.
- Combined with careful key design, cluster mode / Flexible Sharding, and optionally a small Lua wrapper, this lets you build lightweight search/indexing flows on top of existing String data without always paying the cost of new structures.
- Benchmarks show orders-of-magnitude improvements vs non-optimized scans (minutes → milliseconds) and sub‑millisecond end‑to‑end latencies for KEYS+MGET variants in realistic workloads, when scoped to a single hash slot with small per-slot cardinality.
Try it yourself
If you wish to try the above benchmarks, the Github repository containing the code and instructions are here.
Sources
For more on the underlying mechanism, see the glob-style patterns section of the Redis Cluster specification and the KEYS / SCAN docs:
- Cluster spec (glob-style patterns): https://redis.io/docs/latest/operate/oss_and_stack/reference/cluster-spec/#glob-style-patterns
- KEYS command: https://redis.io/docs/latest/commands/keys/
- SCAN command:
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.