Blog
Agentic RAG: How enterprises are surmounting the limits of traditional RAG

Retrieval-Augmented Generation (RAG) has become central to how enterprises build AI systems. It allows LLMs to access and reason over proprietary enterprise data without expensive fine-tuning, making AI practical for production use.
But as enterprises deploy RAG systems, they're hitting limits. Vanilla RAG handles simple queries well but struggles with complexity. It retrieves once, generates an answer, and that's it. There’s no iteration or way to refine when the first pass falls short.
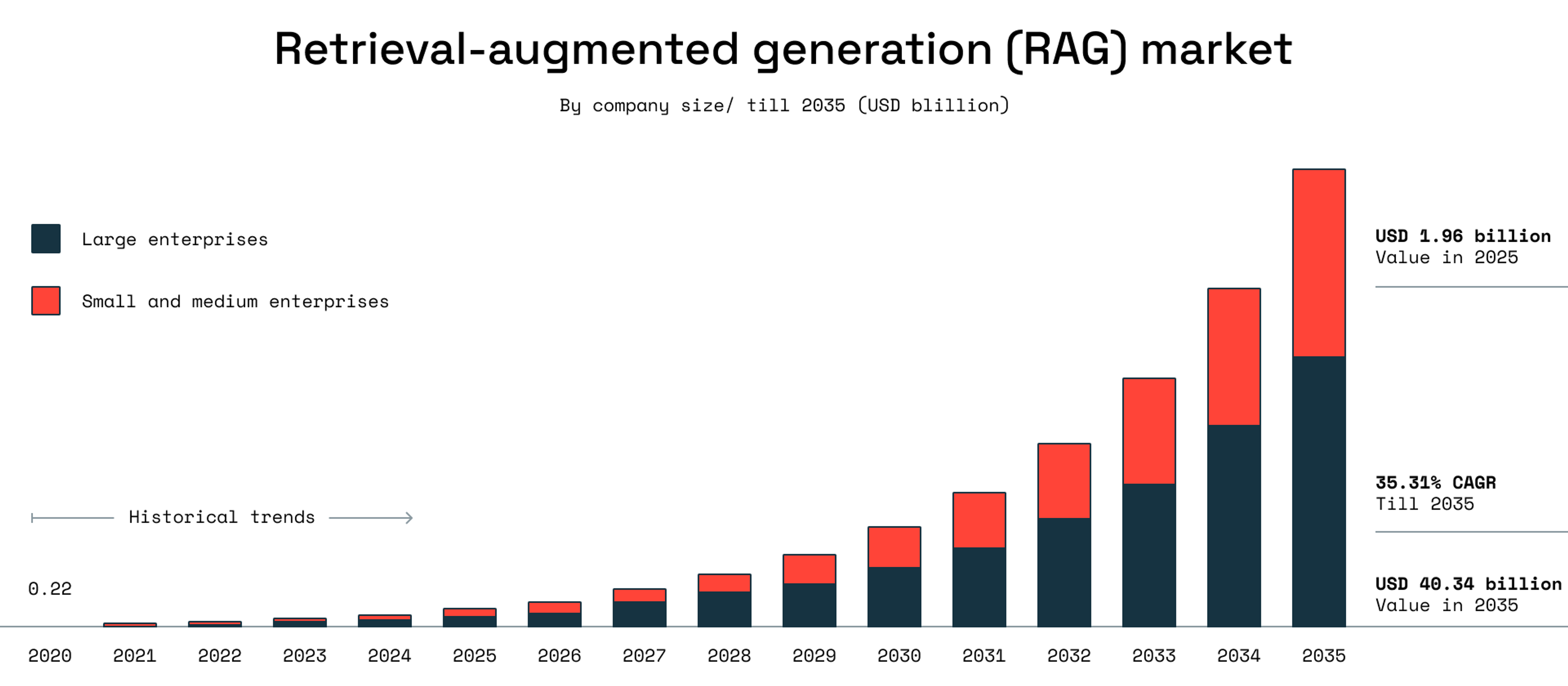
Agentic RAG changes this. It builds on the vision that first drew enterprises to RAG: offering a path to more flexible, intelligent retrieval systems. And the shift is already happening. Google Cloud's 2025 ROI Report found that 52% of enterprises using GenAI now run AI agents in production, with 88% reporting positive ROI. Roots Analysis projects the RAG market will grow from $1.96 billion in 2025 to $40.34 billion by 2035, with large enterprises leading adoption.
To get you up to speed, we’ll cover the basics of agentic RAG, the components that comprise it, when to use it, how to implement it, and the infrastructure you’ll need to support it.
What is agentic RAG?
Agentic RAG goes beyond traditional RAG's single-shot retrieval-and-answer flow. It uses LLMs as agents that can plan steps, refine queries, invoke tools, and draw on memory. Where vanilla RAG retrieves once and passes context to the model, agentic RAG makes retrieval iterative and adaptive: the agent identifies gaps, calls the right tools, and loops until the task is resolved. For enterprises, that shift turns static lookups into dynamic, multi-step problem solving, grounded in trusted data but flexible enough to handle complexity.
Agentic RAG vs vanilla RAG
The excitement around agentic RAG is best understood through vanilla RAG's limitations.
Vanilla RAG combines an LLM with a knowledge retriever to ground the model's output in a trusted data source. Users query via a RAG-based search feature, which triggers the retrieval of relevant documents that the LLM reads to produce and generate an answer. This process has proven effective for simple questions, but complex questions often elude traditional RAG, diminishing its usefulness.
With agentic RAG, however, the LLM isn't a passive answer generator. The LLM takes on an active role; as an agent, the LLM can plan, act, and reason across multiple steps. Rather than just consuming the data it retrieves, the agent can make nuanced decisions, refine its queries, and use tools to add context.
The simplest way to compare the two is to think of vanilla RAG as a static, one-shot, one-pass process, whereas agentic RAG is a dynamic, iterative process that can embrace nuance and tackle complexity.
| Feature | Vanilla RAG | Agentic RAG |
|---|---|---|
| LLM-supported | ✅ | ✅ |
| Search grounded in trusted data sources | ✅ | ✅ |
| Tool usage | ❌ | ✅ |
| Multi-step reasoning | ❌ | ✅ |
| Memory | Limited | Rich |
| Query refinement | ❌ | ✅ |
How agentic RAG works
Query analysis & planning
The agent starts by simplifying complex questions into steps. It figures out what's actually being asked, flags ambiguities, and decides which tools and data sources it needs.
For example, the agent breaks down "What were our Q3 sales in EMEA compared to last year, and what drove the changes?" into: retrieve current Q3 EMEA data, retrieve prior year data, calculate the difference, search for market reports explaining performance drivers.
Dynamic retrieval strategy
The agent adapts as it goes. If the first results come back incomplete or contradictory, it refines the search, tries different sources, or changes tack. Vanilla RAG retrieves once and calls it done. Agentic RAG keeps pulling until it has what it needs.
Quality validation & iteration
After each retrieval, the agent checks its information. Does this actually answer the question? Is it current? Does it conflict with something else? If there are gaps or the confidence is low, it loops back for more context.
Response synthesis
Finally, the agent pulls everything together, combining sources, resolving contradictions, and formatting the output. It keeps track of the conversation through memory, runs any calculations or transformations it needs, and delivers an answer that reflects the full reasoning chain.
Core components of an agentic RAG system
Agentic RAG builds on the same foundation as vanilla RAG (an LLM with function calling) but adds the pieces that make it adaptive. With the addition of agents, agentic RAG can use additional tools when needed and use short- and long-term memory to inform its queries.
Think of the LLM in agentic RAG, as Lilian Weng, co-founder of Thinking Machines Lab, suggests, "as the agent's brain, complemented by several key components," including memory and tool usage.
LLMs with function calling
The LLM is the core reasoning function at the heart of an agentic RAG system. The LLM takes a prompt and produces actions, such as "search for X," and retrieves more information. These actions can include calling a retrieval function to determine when to invoke specific tools, such as an internal vector database, calculators, web browsers, and APIs.
For example, the function call could lead to a vector store and request the retrieval of specific documents. Once the documents, in this example, are returned to the LLM, the information from the documents is fed into the LLM's context window, enabling the agent to continue reasoning.
Many modern LLMs, including GPT-4 and Claude, can use function calling to interact with external tools. ChatGPT's Deep Research feature, for example, can interact with numerous search tools to pull together the research materials users are looking for. There are open-source models, such as Hermes-2 Θ Llama-3 8B and Mistral-7 B-Instruct-v0.3, that provide similar function-calling features, too.
For developers, the key is to look for models that provide function calling as a built-in functionality. Technically, developers can add something approaching function calling via a combination of prompt engineering, fine-tuning, and constrained decoding, but generally speaking, native function calling tends to be much more effective.
Tools
LLMs equipped with function calling can use tools to complete users queries. These tools can include:
- Search engines
- Calculators
- Code interpreters
- Calendars
- Domain-specific APIs
- Web browsers
For RAG, the main tool is always the external knowledge source (typically a vector database and a wealth of internal documents) but additional tooling can transform incomplete answers into useful and impactful ones.
For example, a vanilla RAG tool might enable users to retrieve financial data from a company's database. This might be useful for users familiar with this data, but it may be useless for non-technical users who have an important question but lack the necessary technical skills to parse the data.
With agentic RAG, the system can take the next step of invoking a Python tool to generate a chart or compute a specific statistic from the retrieved data. Agentic RAG might even be able to invoke a visualization tool to turn the data into a readable, shareable format.
Agents
An agent is an AIthat can remember context, break problems into steps, and call tools, all wrapped up with a specific role to play.
In agentic RAG, agents are typically responsible for:
- Receiving user queries and planning out high-level steps.
- Deciding what tools to invoke and in what sequence.
- Running, inspecting, and learning from results.
- Acting on new evidence from documents, calculations, or API calls.
- Repeating these steps until the query is resolved and responding to users.
We can think of agents as autonomous problem solvers able to operate without supervision. Rather than following a one-way path – typically from query to retrieval to response – an agent engages in an active feedback loop. At each step, the agent reviews what it learned and plans the next step. In this sense, agentic RAG shares a closer resemblance to how humans tend to tackle complex questions than it does to the static pattern of a vanilla RAG pipeline.
Not all agents do the same job. Agentic RAG systems typically use one or more of these agent types:
- Routing agents decide where to send a query. They analyze the question and determine which data source or tool is most likely to return useful results. In simpler setups, the routing agent is the only agent, so it picks a source and retrieves information itself.
- Query planning agents handle decomposition. When a user asks a complex, multi-part question, the planning agent breaks it into subqueries, dispatches them (sometimes in parallel), and combines the results.
- ReAct agents combine reasoning and action in an iterative loop. The agent reasons about the next step, takes an action (like calling a tool), observes the result, and repeats until the task is complete. ReAct agents adapt based on what they find.
- Plan-and-execute agents generate a full plan upfront, then execute each step without calling back to the primary agent. This reduces latency and cost while improving completion rates on complex workflows.
In practice, these often combine. A query planning agent might coordinate multiple ReAct agents, each specialized for a different data source.
Memory
Agents use memory to enable more sophisticated reasoning. A couple of examples are:
- Short-term memory (STM): Temporary information relevant to the current session. For example, a short-term memory could include user preferences, previous queries, or context from an active conversation. STM enables the agent to handle follow-up questions, track clarifications, and adapt responses based on session-specific context without re-retrieving prior information.
- Long-term memory (LTM): Persistent context, such as project history, known constraints, or previously solved problems. For example, an LLM could retrieve a solution from a previously-solved problem and use that to help identify an approach for a current issue. LTM typically relies on vector stores—semantic memory that spans sessions—and might include embedded knowledge from prior tasks or examples.
Both short-term memory and long-term memory are especially important in production agentic RAG systems because, in practice, the best implementations of agentic RAG don't just learn from a single query. These systems learn from repeated queries across sessions, conversations, and user histories.
Framework & orchestration (optional, but commonly used)
Agents don't operate in a vacuum but often do so in a predefined environment designed by developers. Many teams use orchestration frameworks to structure agent behavior. Examples of frameworks include:
- LangChain / LangGraph: This framework maps out an agent's internal steps and, as a result, provides traceability, error handling, and loop prevention.
- Microsoft Semantic Kernel: This framework enables developer-friendly abstractions for managing agents' tool calls, memory, and context.
- CrewAI: This framework, focused on multi-agent orchestration, enables developers to coordinate how specialized agents share memory and collaborate to solve increasingly complex tasks.
These frameworks make two very important things possible:
- They make agents more structured and predictable, thus more likely to meet enterprises' reliability standards.
- They make agents easier to debug and troubleshoot, which is often a challenging process without a framework.
This framework does not represent a "must-have" — it's perfectly viable to build agents from scratch — but these frameworks, in practice, can greatly help developers navigate common pitfalls.
When to use agentic RAG over vanilla RAG
Agentic RAG comes with a lot of benefits, but those benefits also come with costs. For certain use cases, though, it's worth it:
- Complex, multi-step questions: Questions with multiple ambiguous parts can lead to retrieval gaps. An agentic RAG approach can iteratively refine searches until it resolves all parts of the query.
- Hybrid data access needs: When working with structured databases, external APIs, and document stores, agents can decide which tool to invoke, as well as when and in what order.
- Conversational continuity: As users ask follow-up questions, agentic memory retains the context from earlier steps, eliminating the need for repeated retrieval of the same information.
- High-stakes decisions requiring verification: Agentic workflows can check retrieved facts, cross-reference multiple sources, or run verification steps before producing a final answer.
Here's where real-world teams are seeing the most value:
- Customer support automation: Agentic RAG systems can handle multi-layered customer support tickets, routing questions, retrieving relevant documentation, and invoking account management tools when needed
- Legal and regulatory research: Law firms can use agentic RAG to find relevant precedents, cross-check statutes, and summarize findings by searching through a series of documents.
- Financial analysis: Financial firms can use agentic RAG to pull data from company filings, cross-reference with external news sources, and invoke tools to generate charts or compute metrics.
There's growing interest in agentic RAG due to the limitations of vanilla RAG. It is far more complex and comes with higher risks, which is why developers should be confident there's a real gap before defaulting to agentic RAG. But if vanilla RAG is too limiting, agentic RAG offers proven value.
Enterprise use cases for agentic RAG
Agentic RAG pays off most in industries where you need to get the right information fast to actually move the needle.
Financial analysis & research
Finance and banking companies use agentic RAG to analyze company filings, cross-reference with market data, and generate investment recommendations. The agent can retrieve financial statements, pull relevant news articles, invoke calculation tools to compute key metrics, and synthesize all its findings into actionable reports.
Legal research & compliance
Law firms use agentic RAG to search case law, identify relevant precedents, and summarize findings across multiple jurisdictions. The agent can understand legal terminology, recognize when statutes have been amended, and trace citation chains across hundreds of documents.
Customer support automation
Enterprises that use multi-layered support tickets use agents to retrieve account information, check product documentation, and invoke diagnostic tools. Agentic RAG systems know how to route questions appropriately, retrieve relevant knowledge base articles, and can escalate to human agents when they reason that confidence thresholds aren’t being met.
Healthcare decision support
In the healthcare field, medical teams use agentic RAG to support diagnosis and treatment planning. The agent pulls patient history, searches the literature for similar cases, checks drug interaction databases, and puts together recommendations grounded in evidence, giving clinicians a second opinion backed by data.
Technical documentation & troubleshooting
Software teams use agentic RAG to help devs debug issues and ship features. The agent searches internal docs, pulls relevant code examples, checks the issue tracker for similar problems, and can even run tests to verify fixes. Less time hunting through wikis, more time writing code.
Advanced RAG techniques
Agentic RAG is one approach to improving retrieval quality, but there are some advanced techniques worth understanding:
Self-RAG allows the model to critique and refine its own output through reflection. It generates an initial response, evaluates whether it answers the query, and retrieves more context if needed. This self-correction loop reduces hallucinations without requiring external validation.
Corrective RAG (CRAG) adds a relevance check between retrieval and generation. Before the LLM generates a response, CRAG assesses whether retrieved documents actually contain useful information for the query. If relevance is low, the system triggers additional retrieval with refined search terms or falls back to the LLM's parametric knowledge. This prevents the model from generating responses based on irrelevant context.
GraphRAG structures knowledge as graphs rather than flat documents, enabling the system to traverse relationships between entities. It follows graph edges to discover relevant context that keyword search might miss. This works well for queries requiring multi-hop reasoning across connected information.
Adaptive RAG dynamically selects between different retrieval strategies based on query characteristics. Simple factual questions might use basic vector search, while complex analytical queries trigger multi-step agentic workflows. The system adapts its approach to match query complexity, balancing speed and accuracy.
These techniques can all combine with agentic RAG. An agentic system might use Self-RAG for quality validation, CRAG for relevance filtering, GraphRAG for relationship queries, and Adaptive RAG for strategy selection. The choice depends on your specific accuracy requirements and acceptable latency trade-offs.
Common challenges in scaling agentic RAG
Agentic RAG brings better search, smarter reasoning, and stronger results on complex queries. But it's not without trade-offs. Teams scaling agentic RAG tend to run into five challenges: latency, cost, reliability, complexity, and overhead.
Latency
More agents means more steps, which can slow things down. The best way to cut latency is caching intermediate results and speeding up state lookups. Tools that help:
- Redis: Ideal for fast, in-memory caching, Redis can provide intermediate results and semantic retrievals to reduce latency.
- GPTCache: Open-source semantic caching that serves previously computed LLM responses to similar queries.
- FAISS: Efficient embedding retrieval and nearest-neighbor search, especially effective when paired with Redis for fast state lookups.
There's a balance to strike. For simple queries, the extra latency might not be worth it. But in most cases, the benefits of agentic RAG justify finding ways to keep things fast.
Cost
Agentic RAG needs multi-step reasoning, and that means multiple expensive LLM calls. Caching tools help by cutting down on repeated calls. Some relevant options are:
- Redis LangCache: This fully managed semantic caching product caches previous LLM outputs and reuses those responses for similar queries, significantly reducing token consumption.
- GPTCache: This tool provides semantic caching, which can reduce the frequency of LLM calls and lower usage costs.
- LangChain's function-call caching: This feature deduplicates external tool invocations, enabling enterprises to avoid costly, repetitive API calls.
Without the right care around design, LLM usage can become very expensive – a problem that extends far beyond agentic RAG. Any enterprise that wants to use generative AI often will have to address the possibility of mounting costs.
Reliability
Agentic RAG can include numerous different agents, but agentic RAG can sometimes face reliability issues if any of those agents fail or loop. Developers can reduce the likelihood of these issues happening by implementing fast fallback mechanisms. Relevant tools include:
- Cloud provider reliability tooling: This category of tools, including ones from Azure, Google Cloud, and Amazon Web Services, ensures that systems can temporarily stop calls and reroute to backups.
- LangChain: This tool provides built-in iteration limits, retry mechanisms, and structured fallback logic, ensuring that agents won't endlessly loop.
- Apache Airflow: This tool offers centralized orchestration with built-in retries, timeouts, and failover strategies for agent tasks.
With fallback mechanisms like these in place, enterprises can be much more confident that the agents involved in agentic RAG systems can operate without failing.
Complexity
Agentic AI, because it involves adding numerous agents to a more foundational RAG approach, can be harder to debug, observe, and monitor than vanilla RAG. Developers can make agentic RAG easier to manage by adding fast and transparent caching solutions that simplify debugging and monitoring work. Relevant tools include:
- LangSmith: This specialized tracing tool provides step-by-step visibility into agent reasoning, tool usage, latency, and errors.
- Langfuse: This open-source observability platform enables the tracing of agent interactions, LLM calls, and the capture of structured logs.
- Datadog, Prometheus, or Grafana: These general-purpose monitoring and logging solutions enable the tracking of structured agent metrics, logs, and performance indicators.
Agentic RAG can be complex to implement and manage, but enterprises, after facing the limitations of vanilla RAG, are increasingly choosing to face the complexity and find the right tools to make agentic RAG more manageable.
Overhead
Agentic RAG, runs multiple agents, which means there has to be coordination between them, which in turn adds overhead. Active-active setups (high-availability architectures where multiple nodes run concurrently) help handle the load. Some tools that help:
- Redis: This tool, particularly its shared memory and pub/sub features, enables real-time shared memory between agents, facilitating fast coordination and event-driven communication.
- Apache Kafka: This tool provides a scalable message broker for asynchronous, decoupled event-driven communication among multiple agents.
- Ray or Apache Airflow: These frameworks provide centralized orchestration, task scheduling, and robust coordination for complex multi-agent workflows.
There’s going to be some amount of overhead in a more complex setup. However, as enterprises struggle with vanilla RAG, the possibility of overhead feels more like a challenge worth addressing than a risk worth avoiding.
Infrastructure considerations for agentic RAG
Agentic RAG has real potential for enterprises, but unlocking it requires the right infrastructure underneath. To get the most out of agentic RAG, design systems that are:
- Low latency: Calling different agents or parts of the system can introduce delays, so your infrastructure needs to minimize latency wherever possible.
- Scalable: Agentic RAG works best when you can run multiple agents at once. But as systems scale, inter-service calls and dependencies between agents pile up, making debugging and reasoning about the system harder. You need infrastructure that can handle many agents without buckling.
- Flexible: Agentic RAG shines when it can work across multiple modalities. That means infrastructure that supports different data types, including text, vectors, and structured data.
Redis can provide numerous infrastructure-level benefits that help with agentic RAG, including:
- Real-time memory, which can support short- and long-term memory for RAG agents.
- High-speed vector search and hybrid queries to support fast, nuanced queries and retrievals.
- Multi-region availability for geo-distributed agents, which increases scalability.
- Semantic caching to reduce redundant lookups and decrease costs.
Agentic RAG is becoming an increasingly popular topic, but the focus of these conversations tends to be on designing or orchestrating agents. The realities of production show that these systems' failure points tend to be lower in the stack.
Memory, coordination, and retrieval latency issues can all make agentic RAG too slow or too cumbersome to be practical. With every agent calling tools, fetching context, and validating results, the real bottleneck tends to be an enterprise's infrastructure, especially under high throughput.
Build the future of retrieval with Redis
Agentic RAG is powerful, but it's not the right fit for every use case. If you're ready to experiment, it offers adaptability, depth, and fine-grained context control. And if you've been using RAG but feel held back by its limits, agentic RAG can help you get to where you thought RAG would take you in the first place.
Infrastructure choices matter here. Bottlenecks are risky, especially under high throughput, and Redis keeps your infrastructure from becoming the limiting factor. It also makes it easier and faster to align data structures with applications, which means higher cache hit ratios.
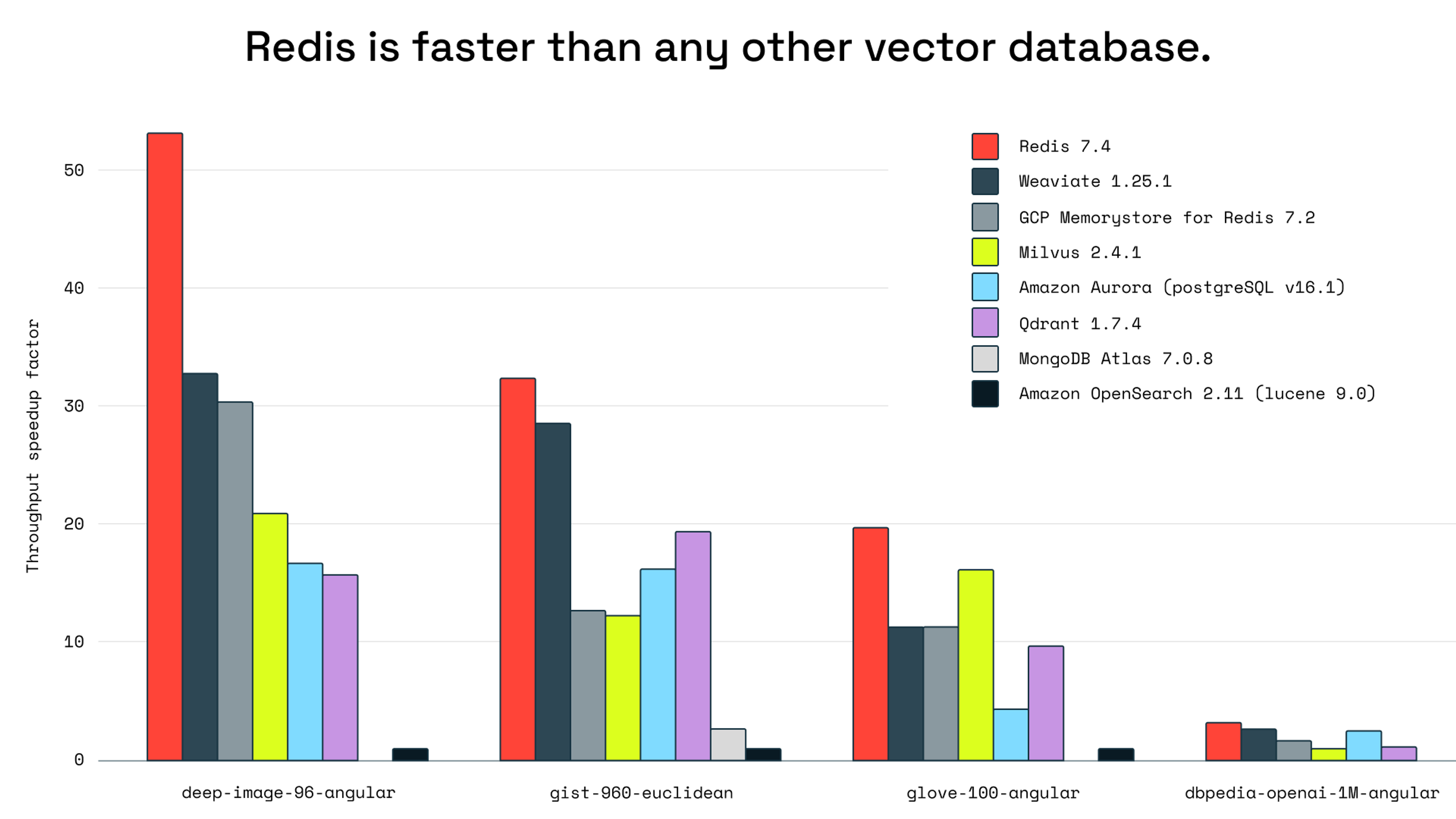
Objective benchmarking shows Redis outperforms all other vector databases. For agentic RAG, where speed and scalability aren't optional, that makes it the fastest choice.
If you're ready to build an agentic RAG system or support an existing one with faster, more reliable infrastructure, you can try Redis for free or book a demo today.
FAQs about agentic RAG
What is agentic RAG?
Agentic RAG uses LLMs as agents that can plan steps, refine queries, invoke tools, and draw on memory to answer complex questions. Unlike traditional RAG's single-shot retrieval, agentic RAG makes retrieval iterative and adaptive. The agent loops until the task is resolved. Instead of a static lookup, you get multi-step problem solving.
How does agentic RAG work?
The agent breaks complex queries into steps, retrieves information dynamically, validates quality after each retrieval, and combines responses from multiple sources. If initial results are incomplete, the agent refines its search and loops back for additional context.
What is RAG vs agentic AI?
RAG grounds LLM outputs in trusted data sources through document retrieval. Agentic AI describes LLMs that can plan, use tools, and act autonomously across multiple steps. Agentic RAG combines both: autonomous agents performing iterative retrieval that adapts based on what the agent discovers.
Is RAG agentic AI?
Traditional RAG isn't agentic AI—it retrieves once and generates an answer. Agentic RAG is agentic AI because the LLM actively plans retrieval strategies, refines queries based on results, invokes tools as needed, and maintains memory across steps. The agent makes decisions and adapts rather than passively consuming retrieved context.
How do you build agentic RAG?
Start with an LLM that supports function calling (GPT-4o, Claude 3.5 Sonnet, or open-source models like Llama 3.2). Add orchestration frameworks like LangGraph or AutoGen to structure agent behavior. Implement vector databases and semantic caching for fast retrieval and memory. Use Redis to provide unified infrastructure for vectors, caching, agent memory, and coordination in one platform.
How do you implement agentic RAG?
Choose your orchestration framework (LangGraph, AutoGen, or CrewAI) and define agent roles and available tools. Implement short-term and long-term memory with vector storage, and add semantic caching to reduce costs. Redis handles the infrastructure layer—Redis Agent Memory Server for memory management, Redis LangCache for managed semantic caching. Start with simple queries, then scale to complex multi-step scenarios.
How do you measure the effectiveness of agentic RAG solutions?
Focus on a few key metrics, such as retrieval precision and recall to ensure you're getting relevant documents, faithfulness to confirm responses stay grounded in source material, and task completion rate for end-to-end resolution without human intervention. Also track tool call accuracy to verify the agent invokes the right tools with correct parameters. Monitor latency by query complexity to identify cost and performance bottlenecks.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.